|
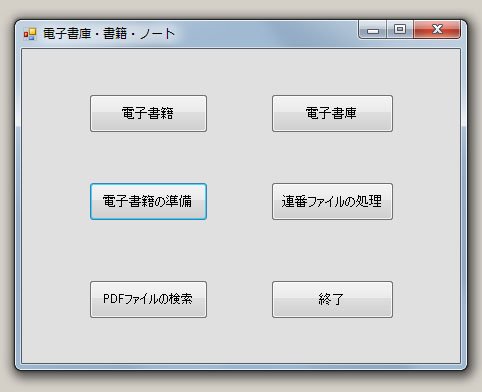
スキャナーやデジタルカメラを利用して、印刷物などから画像情報を取得だけでは、は利用できません。を利用するためには、を利用して、ファイル名の変更などを行なうことが必要です。 「電子書籍」のフォルダーは、「電子書籍」用の画像ファイルと「電子ノート」用のテキストファイルで構成されます。「電子書籍」用の画像ファイルとして、ページ毎のPDFファイルやJPGファイルを使用します。「電子ノート」用のテキストファイルは、3種類のテキストファイルで構成されます。 印刷物の複写によって得られたファイル名は、使用する機材により、ファイル名や連番が付加されます。ファイル名は、利用者が意図するものと限らず、連番も、書籍のページ番号を表すものではありません。そこで、ファイル名や連番の変更が必要となります。 「電子書籍」用のファイルは、印刷物の複写によって得られたファイル名を、“書籍名_連番.拡張子”に変更したものを使用します。ページ番号を表す連番は、1から始まる自然数を用います。 例えば、“日本国憲法バインダ 1.pdf”などのファイル名は、書籍名を“日本国憲法”として、以下のとおりに変更されます。
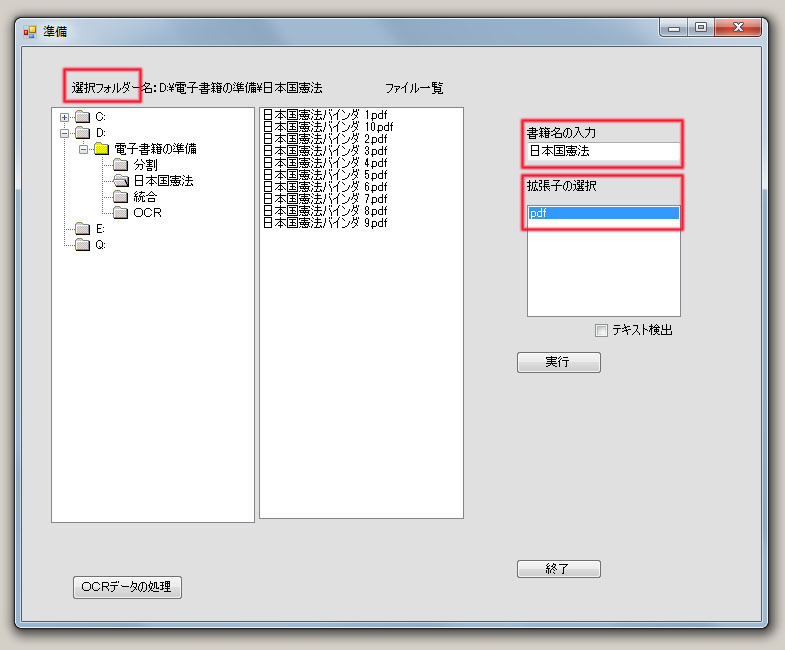
3種類の「電子ノート」用のファイルとして、“書籍名_Index.txt”、“書籍名_Text.txt”、“書籍名_Memo.txt”のテキストファイルが作成されます。 “書籍名_Index.txt”は、目次・索引・栞(しおり)などの情報を記録します。 “書籍名_Text.txt”は、OCRソフトによって得られたテキストデータなどを記録します。 “書籍名_Memo.txt”は、メモ帳として利用します。 これらのファイルの形式は、以下のとおりです。 1&・・・&・・・&改行コード 2&・・・&・・・&改行コード 3&・・・&・・・&改行コード ・・・ n&・・・&・・・&改行コード 1ページ毎の内容は、1行毎に記述されます。各行の先頭の数値は、ページ番号です。 ページの内の改行は、”&”を用います。 例えば、 ”1&国連憲章&序&国際連合憲章は、国際機構に関する連合国会議の最終日の、1945年6月26日にサンフランシ&スコにおいて調印され、1945年10月24日に発効した。国際司法裁判所規程は国連憲章と不可&分の一体をなす。&CR+LF” は、ディスプレイ上で以下のように表示されます。 国連憲章 序 国際連合憲章は、国際機構に関する連合国会議の最終日の、1945年6月26日にサンフランシ スコにおいて調印され、1945年10月24日に発効した。国際司法裁判所規程は国連憲章と不可 分の一体をなす。 (1) 電子書籍用のフォルダーの用意 電子書籍用のフォルダーを作成します。 通常はフォルダーの名前を、書籍名とします。 (2) 画像ファイルの作成 このフォルダーの中に、印刷物の複写によって得られた画像情報を、書籍1ページを1ファイルとして格納します。 画像ファイルとして、PDFやJPG形式のファイルを利用します。 (a) 印刷物の複写で得られたPDFファイルの場合 複写機のスキャナーを用いて書籍を複写して、PDFファイルとして保存します。 スキャナーの利用に際して、原稿の向きによっては、画像の回転が必要な場合があります。 複数ページが、一つのPDFファイルとして出力されることがあります。この場合には、1ページ毎に分割したPDFファイルを作成してください。 (b) JPGファイルの場合 デジタルカメラやスキャナーを用いて、1ページ毎にJPG形式のファイルとして保存します。現在のデジタルカメラは、5000万画素を越える機種もあります。しかし、それを表示するパソコンのディスプレーは、200万画素程度です。従って、文字が判別できる程度なら、不必要に大きな画素で撮影する必要がありません。撮影時に適当な画素数の選択が望まれます。なお、撮影後の画像サイズの変更は、画像処理ソフトを利用します。また、カメラの向きによっては、画像の回転が必要な場合があります。画像処理ソフトを利用してください。 画像を拡大や縮小して表示するのに、JPGよりPDFファイルが有利です。「電子書籍」の表示ソフトで、JPG画像の拡大・縮小機能が利用できますが、それを繰り返すことによる画像の劣化を防ぐ課題が未解決です。必要であれば、JPGファイルからPDFファイルへの変換を行なってください。 (3) OCR情報の作成 OCRソフトを利用して、文字コードをテキストファイルとして取得します。えられたテキストファイルは、電子書籍のフォルダーに格納します。 (4) を利用する このソフトは、以下の準備をします。 (a) 1ページ毎の画像ファイル名を「書籍名_連番.拡張子」に変更する。 (b) 三種類のノート「書籍名_Index.txt」,「書籍名_Text.txt」,「書籍名_Memo.txt」を作成する。 (c) OCR情報を、「書籍名_Text.txt」ファイルに取り込む。 |
| をクリック | 電子書籍のフォルダーを選択 書籍名を入力:デフォルト値はフォルダー名 拡張子を選択して、 | 変更されたファイル名が表示される 電子ノート用のファイルが作成される |
 |  | 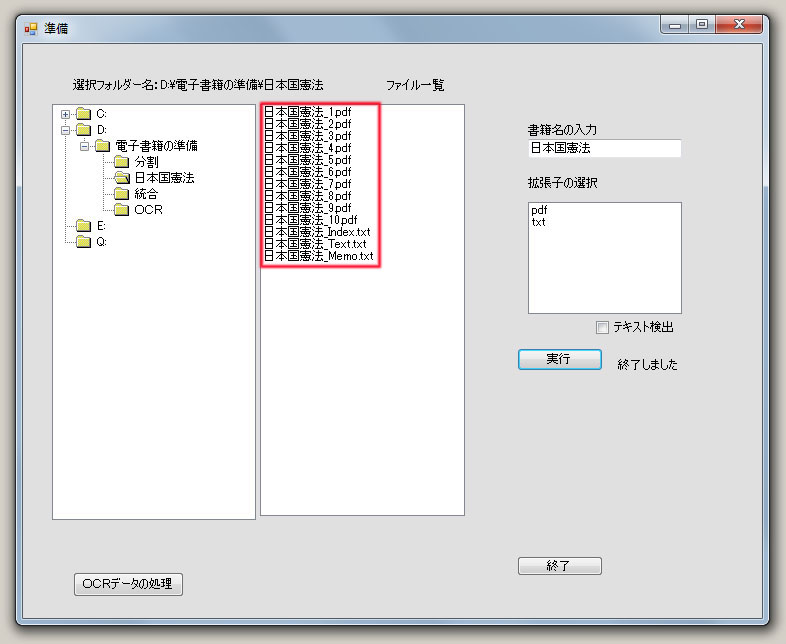 |
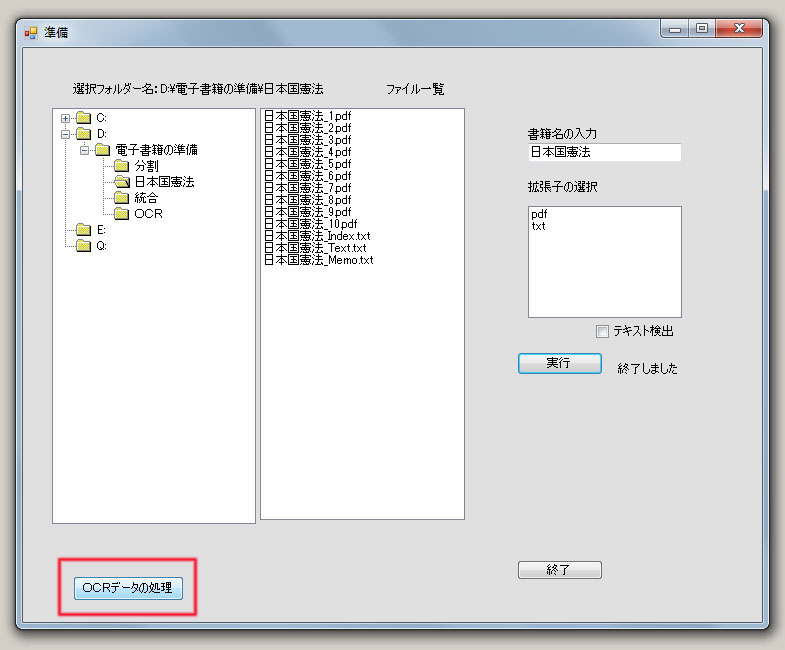
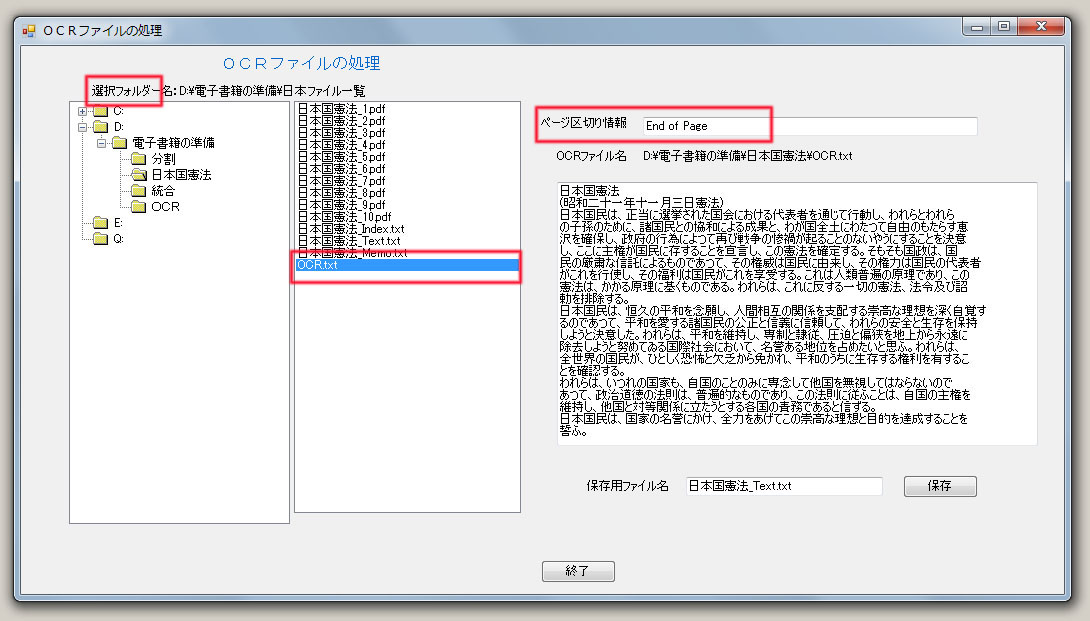
(c) OCR情報を、「書籍名_Text.txt」ファイルに取り込む。
| をクリック | 電子書籍用のフォルダーを選択 OCR用のテキストファイルを選択すると、最初のページが表示されます。 ページセパレータ(ページ区切り情報)を指定して、 |
 |  |
|
電子書籍の確認を行なう が終わったら、を用いて、電子書籍の確認をしてください。 特に、OCR情報の取り込みで、エラーが発生することがあります。 OCR情報の最終ページの内容をキーワードと検索し、電子書籍とテキストが対応しているかの確認を行います。 また、途中のページであっても、、電子書籍とテキストが対応しないことがあります。これは、OCRソフトを利用する際の、連番処理の不都合によります。 ページセパレータ(ページ区切り情報)に関して OCR情報は、1ページ毎に「日本国憲法_Text.txt」のファイルに取り込まれます。この処理に必要なページセパレータ(ページ区切り情報)が、OCRの処理で得られるテキストファイルに含まれていることが必要です。ここで用いたOCRソフトでは、ページの末端に”End of Page”の情報が共通して挿入されています。そこで、ページセパレータのデフォルト値として、”End of Page”を使用しています。共通のページセパレータが存在しないテキストファイルには、利用者が挿入することが必要となります。 スキャナーの処理枚数に制限がある場合 スキャナーによっては、一度に処理できる枚数に制限がある場合があります。 例えば、最大の処理枚数が1000ページの場合、1000ページごとに、統合型PDFファイルが生成されます。このような場合、複数の統合型PDFファイルを、ページ毎に分割して、電子書籍用のフォルダー用に保存します。 例えば、1500ページの書籍の場合、以下のような手順で処理を行います。 ① この場合、二つの統合型PDFファイルができます。二つのフォルダーa,bを作成します。 ② 「Acrobat Standard」などを利用して、最初にできた統合型PDFファイルを分割して、フォルダーaに格納します。 次にできた統合型PDFファイルを分割して、フォルダーbに格納します。 ③ を利用して、aのフォルダーでは書籍名を”a”,開始頁番号を"1000"とします。 bのフォルダーでは書籍名を”a”,開始頁番号を"2000"とします。 ④ 電子書籍用のフォルダーに、aとbのフォルダーに含まれるファイルをコピーします。 ⑤ 最後に、を用いて、電子書籍用のフォルダーを開き、処理をします。 複数の書籍を統合する。 百科事典や全書などは、大量の情報を取り扱っています。この場合、利用上の都合を考慮すると、数冊から数十冊に分冊されています。電子書籍を利用する場合は、分冊用のフォルダーを利用するよりは、一つのフォルダーを利用した方が便利です。このような場合、以下の処理を行います。 ① 1冊ずつ、電子書籍を作成します。 ② 1冊ずつの電子書籍を残すことや誤処理を考慮して、新しいフォルダーを作成し、そこに全冊をコピーします。 ③ を利用します。書籍名は、総て共通にして、例えば ”a”とします。 開始頁番号は、順次に、"1000","2000","3000", ・・・などとします。 但し、1冊が1000ページを越える本がある場合には、"10000","20000","30000", ・・・などとします。 ④ 電子書籍名を付けた別のフォルダーに、総てのファイルをコピーします。 ⑤ 最後に、を用いて処理します。 飛び飛びの連番が含まれる場合も処理が可能です。最大のページ数は、2万ページに設定しています。 ⑥ OCR情報を順次結合したテキストファイルを作成し、を行ないます。 ページの削除を行なう 白紙のページなどを削除したい場合は、以下の手順をとります。 ① 削除したいページのファイルを、右クリックで「削除(D)」の機能を利用して、削除します。 ② を用いて処理します。 ③ 削除した部分のOCR情報を、OCRのテキストファイルから削除し、を行ないます。 ページの挿入を行なう スキャナーの誤動作などで、複数のページが欠落することがあります。 この場合、欠落したページを挿入することが必要です。 電子書籍を作成後に、欠落に気付いた場合は、以下の対処を行います。 ① 電子書籍用のフォルダーに対して、を利用して、連番ファイル名の変更を行います。 欠落ページの枚数を考慮して、「増分」値を決めます。 10ページ未満であれば、「増分」値を10とし、 10ページから100ページ未満であれば、「増分」値を100などを指定します。 ② 挿入するファイルを収めた別のフォルダーに対して、を用います。 書籍名は、①の手順の書籍名とします。 開始頁番号は、挿入箇所の”連番+1”とします。 ③ 挿入するファイルを、電子書籍用のフォルダーにコピーします。 ④ 電子書籍用のファイルから、再度OCR情報を取得します。 ⑤ とを用いて、電子書籍を作成します。 |